As a developer familiar with traditional application development and testing, you may face new challenges when working with applications based on large language models (LLMs). These applications, which produce nondeterministic output, require a different evaluation and testing approach than conventional software.
There are two aspects to consider here:
| LLM model evaluation | LLM-based application evaluation |
|---|---|
Focuses on the raw capabilities of the language model itself using standardized benchmarks and metrics | Focuses on how well the entire application, which includes the LLM as a component, performs in real-world scenarios and meets specific business requirements |
Developing LLM-based applications involving AI agents and retrieval-augmented generation (RAG) pipelines introduces challenges that traditional testing methods do not sufficiently address. These challenges include:
| Prompt effectiveness | Memory recall | Application performance |
|---|---|---|
Testing agent prompts for effectiveness and consistency | Evaluating memory systems for information retention and retrieval | Optimizing product-level performance in terms of accuracy, speed, and cost |
This article focuses on LLM-based application evaluation and guides you through developing and implementing an LLM application evaluation process. We cover the following:
- The components of an effective evaluation framework
- Best practices for creating evaluation datasets
- Choosing appropriate metrics for your specific use case
- Establishing scoring criteria and automation strategies
By the end of this article, you'll understand how to approach LLM application evaluation, enabling you to make the right decisions about model selection, application design, and optimization. We use comprehensive evaluation tools and techniques as part of the process.
Summary of key LLM application evaluation concepts
| Concept | Description |
|---|---|
LLM model evaluation vs. LLM application evaluation | LLM models are evaluated against standard benchmarks like MMLU, GPQA, or MATH. However, in real-world applications, it is necessary to focus on practical aspects like accuracy and consistency specific to the use case, along with cost-effectiveness and response speed. While benchmarks offer insights into model capabilities, they may not reflect real-world performance. Evaluating LLMs effectively requires focusing on application-specific scenarios to ensure outcomes align with the intended use. |
Creating an evaluation dataset | Developing an evaluation dataset for your LLM application is crucial. Examples can be manually curated, synthetically generated, or derived from application logs. Tools like Langfuse and LangChain's LangSmith offer capabilities to generate and manage such datasets efficiently. |
Choosing evaluation metrics | Selecting the right metrics is key to understanding LLM application performance. Take into account the following factors: _ Completeness:Focus on how well the system captures all relevant information and addresses user queries. Precision and recall are key to ensuring the output is accurate and covers all necessary aspects. Retrieval-augmented generation (RAG) helps by accessing correct, relevant information. _ Text quality:Evaluate how closely the generated text aligns with the intended meaning or reference. _ Memory performance:Assess the ability to utilize long-term memory and improve accuracy by recalling and applying relevant past interactions or information. _ Factual accuracy:Minimize incorrect or fabricated outputs by evaluating factual consistency (e.g., by using TruLens). Retrieval mechanisms help ground responses in real data, reducing hallucinations. * User preferences:Capture subjective elements like how well the system follows instructions, maintains tone, and meets user expectations through qualitative human feedback. |
Scoring and passing criteria | Ultimately, you want to be able to automate your LLM application testing so that you know it is performing as expected. Scoring provides a quantitative measure of LLM application performance. It can be used to develop pass/fail criteria that can be used within a CI/CD pipeline to evaluate whether an LLM-based application is performing as expected. |
Automating evaluation in CI/CD pipelines | Automate LLM application evaluation using CI/CD pipelines with tools like Hugging Face's transformers and datasets library to ensure continuous monitoring of performance metrics, response time, and adherence to predefined thresholds. |
LLM-based application evaluation best practices | When evaluating an LLM-based application, it's crucial to follow structured best practices that ensure thorough and accurate assessment, such as the following: _ Use comprehensive LLM evaluation metrics:Traditional metrics offer surface-level analysis, while advanced tools like G-Eval assess deeper semantic accuracy, providing a more complete evaluation. _ Optimizing tradeoffs for LLM performance:Balance model size against latency and quality against cost to maximize performance and resource usage. * Understand the available frameworks:Use model benchmarks (e.g., Hugging Face evaluate, EleutherAI LM Evaluation Harness, and Stanford's HELM) and application frameworks (e.g., LangSmith, Langfuse, and OpenAI Evals) to assess the LLM model and its real-world application. |
LLM model evaluation vs. LLM application evaluation
While LLM model evaluation focuses on LLM models' capabilities, LLM application evaluation emphasizes how the model performs in specific scenarios aligned with business needs, user requirements, and application objectives. Since LLMs produce probabilistic and nondeterministic outputs, their responses can vary even with the same prompt, making consistent evaluation challenging.
These nondeterministic outputs make evaluating an LLM-based application difficult. Setting parameters like temperature to 0 or using seeding (if the model supports it) can create more deterministic behavior, but slight prompt variations can still produce significantly different results.
Application evaluation must also consider tradeoffs like cost (e.g., computation and resource usage), latency (response time), and accuracy (how well the model meets application-specific needs).
Comparison to traditional application testing
To understand the unique aspects of LLM application evaluation, let's compare it to traditional application testing:
| Aspect | Traditional testing | LLM application evaluation |
|---|---|---|
Requirements | Well-defined, deterministic | May include subjective or context-dependent criteria |
Test cases | Static, predefined | Dynamic; may require human evaluation |
Automation | Straightforward to automate | Automation can be complex, often requiring LLM-based evaluation |
Consistency | Expected to produce identical results | Results may vary; focus on statistical consistency |
CI/CD Integration | Standard practice | Requires careful design to handle nondeterministic outputs |
LLM evaluation process
The diagram below outlines an LLM evaluation process. An evaluation dataset is created to score the output from an LLM-based application for given inputs. These scores are checked against minimum thresholds to generate passing and failing criteria. Integrating this flow within a CI/CD pipeline allows an LLM-based application to be evaluated as it develops, as shown below.
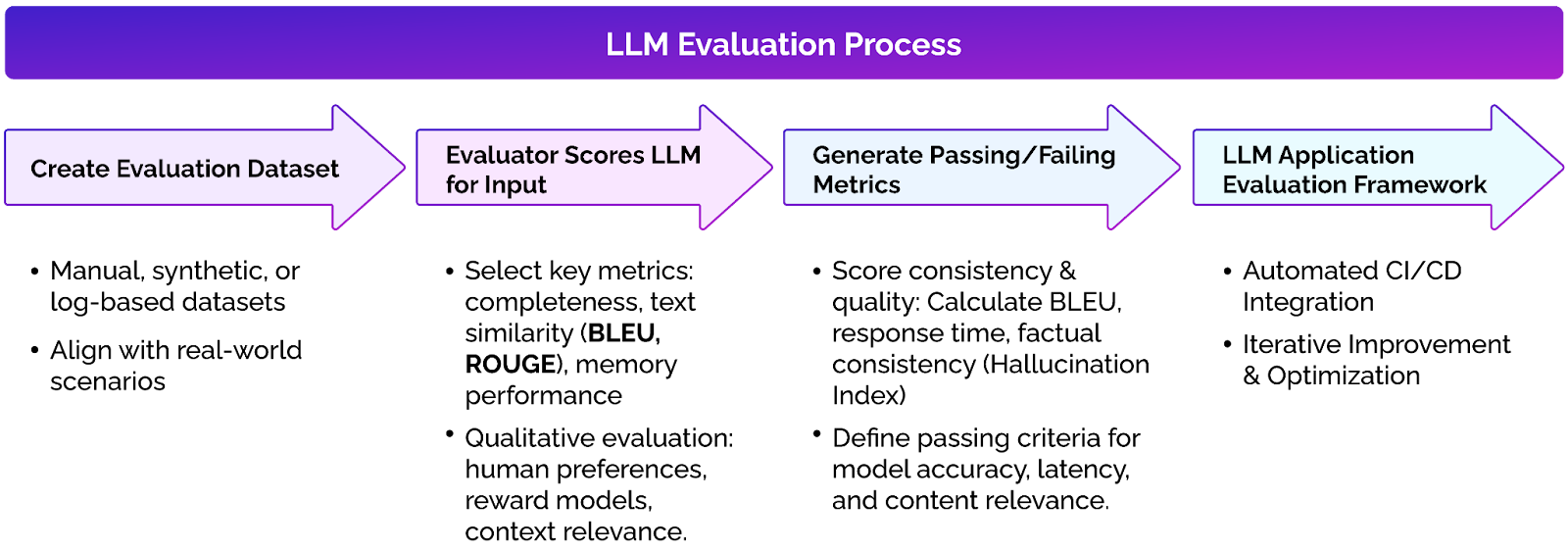
LLM evaluation process in real-world use scenarios
Evaluating LLM-based applications
Effectively evaluating an LLM application typically includes the following components:
- Prompt evaluation: Assessing the effectiveness of prompts in guiding the LLM to produce desired outputs
- Memory performance: Evaluating how well the application retains and utilizes information over time, especially for long-term memory systems
- RAG pipeline assessment: For applications using retrieval-augmented generation, evaluating the quality and relevance of retrieved information
- Latency and efficiency: Measuring response times and resource utilization to ensure that the application meets performance requirements
- Output quality: Assessing the relevance, coherence, and accuracy of the LLM-generated content
- Task completion: Evaluating how well the application accomplishes specific tasks or goals
Creating an evaluation dataset
Effectively evaluating LLM applications requires datasets that reflect the types of queries and outputs your model will encounter in real-world usage. Building such a dataset for your evaluation framework allows you to test model performance across various scenarios and edge cases. In this section, we'll discuss several approaches to creating evaluation datasets.
Manual creation
Manually curating a dataset allows for high-quality, targeted examples but can be time-consuming. By manually adding examples, you can test for edge cases, expected behavior, and specific user queries critical to the application.
Generating synthetic data
While manual dataset creation ensures quality, it is not always scalable for large datasets or continuous evaluation. Generating synthetic data using existing LLMs can help expand the dataset quickly while maintaining relevance.
In this example, we use an LLM like OpenAI's model to automatically create question-and-answer pairs on a specific topic. This can help generate a large volume of contextually rich examples that align with your LLM's focus area.
Using tools like Langfuse and LangSmith
Beyond serving as powerful evaluation frameworks, these two tools also facilitate efficient dataset creation and management:
- Langfuse: Streamlines evaluation dataset creation by logging all interactions with your LLM, providing context-rich data for analysis and performance assessment
- LangSmith: Allows you to tag and categorize dataset entries, making it easier to identify areas of improvement and automate future evaluations
Choosing evaluation metrics
A comprehensive approach to choosing the right evaluation covers various areas, ensuring that the evaluation aligns with the application's functional needs and quality requirements. Here's how you can break down these metrics.
Completeness
- Precision and recall: Precision measures the correctness of the LLM's output, while recall measures how well the model captures all relevant information. These metrics are relevant only for classification-based LLM tasks, where evaluating the model's ability to correctly classify outputs is essential.
- Coverage: This metric ensures that the LLM doesn't overlook any parts of a prompt or question. Coverage is particularly important for systems needing exhaustive responses.
- Role of retrieval-augmented generation (RAG): Integrating a RAG framework can significantly enhance completeness by enabling the LLM to retrieve relevant and correct information from a knowledge base. This helps minimize "hallucinations" (false or misleading outputs) and ensures that responses are grounded in accurate data.
Text similarity metrics
These metrics assess how well the model-generated output aligns with the intended output (or the ground truth). These metrics can range from traditional approaches focusing on surface-level comparisons to more advanced techniques that consider deeper semantic meaning.
Traditional metrics
These metrics are best used when evaluating tasks that involve clear reference texts, like translation or summarization. They provide a quantitative measure of how closely the generated text matches the expected output based on surface-level similarities like word overlap. Examples include:
- Bilingual Evaluation Understudy (BLEU): Measures the overlap of n-grams between the generated text and a reference; commonly used for translation and text generation tasks.
- Recall-Oriented Understudy for Gisting Evaluation (ROGUE): Focuses on recall and is widely used in summarization tasks. It looks at how well the generated text captures the essence of the reference text.
- Metric for Evaluation of Translation with Explicit ORdering (METEOR): This metric considers stemming, synonyms, and word order, providing a more nuanced evaluation of text similarity compared to BLEU.
Advanced semantic metrics
These are more suitable for complex tasks where deeper semantic understanding is needed, such as when evaluating responses that involve reasoning, factual accuracy, or context alignment. Here are some examples:
- G-Eval: This recently introduced metric evaluates the generated text by considering more a profound semantic understanding rather than surface-level matches.
- RAG Alignments (RAGAs): This metric aligns responses with retrieved facts, offering a deeper assessment of content accuracy and relevance in RAG-based LLM applications.
Memory performance
Evaluating memory performance is critical for applications that rely on context and user history to provide accurate, relevant responses. This involves assessing short-term memory (contextual understanding within a single session) and long-term memory (retaining information across multiple interactions).
Long-term memory is particularly important for chatbots and AI agents because context must be preserved across sessions.
Zep is a memory layer for AI agents that generates a knowledge graph from user interactions and business data. Developers can retrieve facts from the knowledge graph, improving response quality by grounding the LLM in the most relevant historical data.
Using Zep memory APIs
Persisting memory: The Memory API allows messages to be stored in a chat session , keeping the conversation context intact.
Retrieving memory: You can easily retrieve memory artifacts, such as recent messages and relevant facts, ensuring that the LLM leverages the correct context.
Fine-grained memory search: With the Search API, you can conduct semantic searches across all sessions or specific user interactions, enhancing the LLM's ability to fetch relevant information. It supports reranking results using techniques like maximum marginal relevance (MMR).
Hallucination index
One of the challenges with evaluating LLMs is ensuring factual consistency and minimizing hallucinations (where the model generates incorrect or fabricated information). Hallucinations can impact an application's trustworthiness, especially in fields requiring high accuracy, like healthcare or finance. Here are some relevant considerations:
- Factual consistency and accuracy: Track the rate at which an LLM generates false, misleading, or fabricated information. Hallucinations can significantly affect the trustworthiness of a model.
- Reducing hallucinations through retrieval: Using retrieval-based frameworks (like RAG) can help reduce hallucinations by grounding responses in factual, external data. The lower the hallucination index, the more reliable the LLM is for applications that require factual accuracy.
Task-specific metrics
When evaluating LLM-based applications, the focus should be on metrics directly related to the application's use case and goals.
Safety and ethics metrics
-
Toxicity and bias detection: This approach ensures that LLM outputs are free from offensive or biased language, making the model safe for deployment. While toxicity is less of a concern in modern LLMs due to improved training techniques, filtering, and processes like Reinforcement Learning from Human Feedback (RLHF), monitoring outputs to ensure safety remains important.
Hugging Face's Evaluate library (with toxicity metric) offers prebuilt metrics for analyzing content for toxic language and biases.
-
Factuality and hallucination Index: Measures how frequently the model generates factual inaccuracies or hallucinations. TruLens provides real-time analysis of LLM outputs to detect and minimize hallucinations.
Task completion and instruction-following metrics
- Instruction adherence: Evaluates how well the model follows provided instructions and completes the task as intended.
- Prompt Layer: Monitors how LLMs adhere to structured prompts, which is useful for instruction-heavy applications.
Human preferences and ratings
Human evaluation offers deeper insights into how well the LLM follows instructions, maintains tone, and delivers contextually accurate responses. By incorporating human preferences and ratings, developers can fine-tune LLMs to align more closely with real-world user expectations:
- Going beyond automated metrics: While metrics like BLEU or ROUGE measure surface-level similarities, human evaluation can capture more subtle qualities, such as how well the LLM follows instructions, aligns with the tone of a conversation, or delivers helpful and contextually appropriate content.
- Qualitative ratings and human-in-the-loop assessment: Gathering human ratings allows you to assess the subjective quality of outputs, ensuring that models are aligned with real user expectations and experiences.
- Rewarding models using human feedback: Tools like GPT-4o or o1-preview can facilitate in-depth evaluation based on human preferences, which can be crucial for refining and improving LLM behavior. Such feedback helps in training reinforcement learning models where the LLM is rewarded for generating high-quality, relevant, and contextually accurate responses.
Scoring and passing criteria
Defining objective criteria for LLM application performance helps ensure consistent and measurable outcomes. Response accuracy, latency, and factual consistency should be assessed against preset thresholds to determine whether the application meets the desired performance standards:
- Performance thresholds: Set minimum scores for key evaluation metrics like accuracy, consistency, and response time. For example, factual accuracy might need to exceed 0.8, while response times should stay under 500 milliseconds.
- Pass/fail system: After each evaluation, the results are compared to the predefined thresholds. If the application consistently meets or exceeds these values, it passes. Otherwise, it requires further refinement.
- Automating score calculations: Use performance metrics to automatically compute results, enabling continuous monitoring and quality control within your application pipeline.
The LLM application will align with performance expectations by implementing these criteria into the evaluation framework.
Automating evaluation in CI/CD pipelines
Here's an example of how you might automate LLM evaluation in a CI/CD pipeline using Python and GitHub Actions. The setup uses Hugging Face transformers for LLM inference, the datasets library for data, and evaluate for metrics.
This code block tests the model's performance by measuring text generation quality (using BLEU score) and response time. It generates responses based on input from the SQuAD v2 dataset, compares them to reference answers, and checks if the average BLEU score is above 0.7 and the response time is below 500 ms to determine success.
GitHub Actions workflow
This workflow automates the evaluation process every time code is pushed or a pull request is made to the main branch.
It starts by running tests on each push or pull request, ensuring that performance metrics like BLEU score and response time are automatically integrated into the CI/CD pipeline.
LLM-based application evaluation best practices
Use comprehensive LLM evaluation metrics
When evaluating LLM performance, a balanced approach combining traditional techniques and newer LLM-based evaluations offers deeper insights. Here's a comparison of the two.
Traditional metrics like ROUGE/BLEU are widely used for text similarity by measuring n-gram overlap. They are effective for basic comparison but often surface-level, focusing on syntactic structure rather than semantic content. Meanwhile, LLM-based evaluations like G-Eval (within the DeepEval Framework) use LLMs with chain-of-thoughts (CoT) to assess outputs based on custom criteria. They are highly adaptable and able to evaluate various contexts with human-like accuracy.
The code below shows a quick overview of how G-Eval can be implemented using DeepEval for a metric like correctness:
Optimize tradeoffs for LLM performance
Exploring key tradeoffs to optimize performance and align with application goals is crucial when evaluating LLM applications. A formal evaluation framework helps developers balance the following:
- Model size vs. latency: Larger models often provide better quality but result in increased response times and higher resource usage.
- Output quality vs. cost: High-quality outputs require more computational power, leading to higher operating costs.
- Generalization vs. specialization: General-purpose models may handle various tasks but might not perform as well as specialized models for domain-specific tasks.
By quantifying these tradeoffs, you can make informed decisions on model selection, prompt design, and performance optimization based on their specific application needs.
Understand the available frameworks
A key decision when developing an LLM-based application is choosing which LLM models will be used by your application. This decision will depend on the purpose of your LLM application. The following LLM model evaluation frameworks provide a way to benchmark the performance of LLM models:
- Hugging Face evaluate library: This library has a rich set of built-in metrics and tools for evaluating LLMs across tasks like text generation and classification.
- EleutherAI's LM Evaluation Harness: A framework designed for few-shot and zero-shot evaluation on a wide range of benchmarks and tasks.
- Stanford's Holistic Evaluation of Language Models (HELM): Provides tools for analyzing LLM performance across multiple dimensions and scenarios.
When it comes to testing the performance of the entire LLM-based application, the following are examples of frameworks:
- LangSmith (LangChain): Supports logging, tracing, and evaluating application-specific LLM behaviors, offering tools to fine-tune and assess model performance in production settings
- Langfuse: A platform for tracking LLM application responses, analyzing model behavior, and generating synthetic datasets for better evaluation.
- OpenAI's Evals: A framework that allows a developer to test LLM outputs against specific benchmarks and evaluate how well they meet the application's functional needs.
Final thoughts
Structured evaluation is crucial for developing robust and reliable LLM-based applications. Here are the relevant key takeaways:
- Combine model-level and application-level evaluations for a comprehensive assessment.
- Create evaluation datasets that reflect your specific use cases and user interactions.
- Utilize a mix of traditional and advanced metrics to capture different aspects of performance.
- Integrate evaluation into your CI/CD pipeline for continuous quality assurance.
- Use evaluation results to guide ongoing refinement of your LLM application.
Implementing a structured evaluation framework can ensure that your LLM applications perform well on standard benchmarks and deliver real-world value to your users.